

OLAP Data cube concepts
Introduction
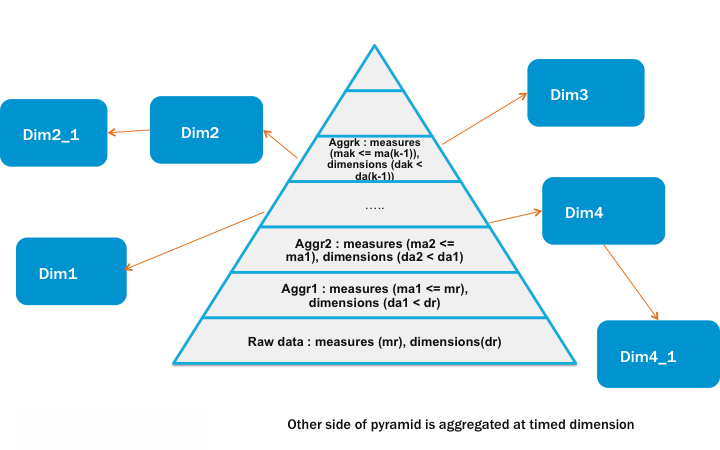
Typical data layout in a data ware house is to have fact data rolled up with time and reduce dimensions at each level. Fact data will have dimension keys sothat it can be joined with actual dimension tables to get more information on dimension attributes.
The typical data layout is depicted in the following diagram.
Lens provides an abstraction to represent above layout, and allows user to define schema of the data at conceptual level and also query the same, without knowing the physical storages and rollups, which is described in below sections.
Metastore model
Metastore model introduces constructs Storage, Cube, Dimension, Fact table and Dimtable, Partition. Below we'll provide a brief indroduction of the constructs. You're welcome to checkout the javadoc. You'll find corresponding classes for each of the construct. The entities can be defined by either creating objects of these classes, or by writing xmls according to their schema. The schema is also available in javadoc.
We have followed a convention in naming classes for constructs, class for a Storage is called XStorage and the xml root tag is x_storage. If storage is part of a bigger xml where root tag is some other construct, then the tag is storage. So in all xmls for lens, all and only the outer most tag are x_* and other tags are not.
Storage
Storage represents a physical storage. It can be Hadoop File system or a data base. It is defined by name, endpoint and properties associated with.
Field
A Field has a name, a display string and a description. Field has the following sub types
Measure
A measure is a quantity that you are interested in measuring. Measure is a field having a default aggregator, a format string, unit, start time and end time. Can also have min and max value.
Dim Attribute
Dim Attributes are not measured, they are more like properties of your data. e.g. Location, user name etc.
- A dim attribute can be as simple as having name and type. // Base Dim Attribute
- A dim attribute can also refer to a dimension // Referenced Dim Atrribute
- A dim attribute can be associated with an expression // Expression Column
- A dim attribute can be a hierarchy of dim attributes. // Hierarchical Dim Attribute
- A dim attribute can define all the possible values it can take. // Inline Dim Attribute
Expression Column
Expression column has one or many expression specs. So you can declare one expression field is specified by one expression for some time, and another for other times.
Join Chain
A join chain is a directional path between two conceptual tables. So if a conceptual table t1 has a chain jc to conceptual table t2, t1 can access t2's fields by saying jc.<t2_field_name>.. A join chain consists of one or more Join paths. A path is defined by sequence of edges where an edge is defined like table1.some_field=table2.some_field. In a path, end table of one edge should be same as start table of next edge.
Conceptual Tables
Conceptual tables are a set of fields. Two types of conceptual tables are defined:
Dimension
A Dimension is a a conceptual table which only contains dim attributes, expressions and join chains.
Cube
A cube is a conceptual table which contains dim attributes, measures, expressions and join chains.
Cubes are of two types:
Base Cube
Base cubes contain full description of all its fields.
Derived Cube
A derived cube will have subset of measures and dimensions of a base cube. User can query derived cube as well, very similar to base cube. For a derived cube, user would specify set of measure names and dimension names only, the definition of measure/dimension will be derived from base cube. All the measures and dimensions of derived cube can always be queried together, whereas all measures and dimensions of parent cube may not be allowed to query together.
Derived cubes can act as a constraint over which fields can be queried together.
Logical Tables
Cubes and dimensions are just collection of fields, it's the highest level abstraction on the underlying data. Logical tables are one level down in the heirarchy of abstraction. A logical table belongs to a conceptual table and can have a subset of fields of the conceptual table. There are logical tables for both the types of conceptual tables. conceptual tables have fields, at logical table level we call them columns. A column is not a measure or dim attribute or expression. A column just has name and data-type. At this level, the distinction of dim attribute, measure and expression goes away. A logical table can declare to have any of these as a column. Logical tables drop the concern of of join chains fully, they are taken care at conceptual table level. Logical tables also drop the concern of expressions partially. Expression fields can be present on a Logical table as a column. Or the sub-fields of the expression field can be present on a logical table as columns and the expression field can be derived using them.
A logical table can be present on multiple storages. A logical table present on a storage is called a physical table or a storage table. The corresponding two types of logical table for conceptual tables are as below:
Dimension tables
Dimension Tables are associated with Dimensions. They can be available in multiple storages.
Fact Tables
The fact table is associated with cube, specified by name. Fact can also be available in multiple storages. The fact will be used to answer the queries on derived cubes as well. Typically facts will belong to only base cubes and derived cubes will inherit all the facts of the base cube.
Storage table
The logical tables present on a storage is called a storage table It will have the same schema as fact/dimension table definition. Each storage table can have its own storage descriptor. As mentioned below, each storage table has any choice of update periods. A storage table can be partitioned by columns. Usually partition columns are dim attributes. They can be timed dim attributes or non time dim attributes. Other properties can be found in the javadoc for storage descriptor.
Physical tables are not defined separately, they are part of the schema of logical tables as storage_tables.
- Naming convention
The name of the storage table is storage name followed fact/dimensions table, seperated by '_". Ex: For fact table name: FACT1, for storage:S1, the storage table name is S1_FACT1 For dimension table name: DIM1, for storage:S1, the storage table name is S1_DIM1
- Update Period
Fact or dimension tables are available on some storages, on each storage, the physical table can be updated at regular intervals. Supports SECONDLY, MINUTELY, HOURLY, DAILY, WEEKLY, MONTHLY, QUARTERLY, YEARLY update periods. Support for CONTINUOUS update period is also added but might be incomplete till 2.4 release.
- Partition
So given a storage table and one of its update periods, data is supposed to be registered at a fixed interval. The construct for this is called a partition. You can register a single partition or multiple partitions together. Once registered, the partition(s) can be updated as well.
So implementation-wise the partitions are stored as partitions in hive metastore. For optimization purposes, lens also keeps the most crucial info cached. Here the difference between fact storage tables and dim storage tables becomes significant.
The corresponding physical tables for the logical tables defined above are:
Dim storage tables
Dimension storage table is the physical dimension table for the associated storage. Dimension storage table can have snapshot dumps at specified regular intervals or a table with no dumps, so the storage table can have zero or one update period.
If the dimension storage table is being updated regularly, older partitions are expected to have lesser data than latest partitions. Examples could be, country id to country name mappings. Newer partitions are supposed to contain at least equal --- or, possibly more --- number of mappings than older partitions. Once a partition is registered, all the older partitions become obsolete.
So in accordance with this, while registering partition, lens registers an additional partition with value latest which has path same as the actual latest partition. So promoting that dim storage tables are always supposed to be queried with latest partition. This is reflected in lens's query translation logic where only latest partition is queried.
Since only one partition is relevant for dim storage tables, lens maintains a hash map for quicker lookup of latest partition.
Fact storage tables
Unlike dim storage tables, all partitions in fact storage tables are relevant and queryable. So there is no latest partition. Instead, lens maintains something called Partition Timeline. They are better explained in this wiki page
Here we'll explore some of the things that you need to be aware of to interact with timelines as a lens user.
Timelines are stored in storage table's properties, which is again cached in memory. Since one fact storage table can have multiple update periods and partitions registered for them can be different, there is need to have timelines for all update periods. Also one storage table can have multiple partition columns. So timelines need to be present for all partition columns too. So for one fact storage table, if x is number of update periods and y is number of partition columns, there will be x*y timelines for it.
You can see the current timeline of the fact by this rest api
Alternatively, on cli you can view like this:
lens-shell>fact timelines --fact_name sales_aggr_fact2 EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=mydb_sales_aggr_fact2, updatePeriod=DAILY, partCol=dt, all=null), first=2015-04-12, holes=[], latest=2015-04-12) EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=mydb_sales_aggr_fact2, updatePeriod=DAILY, partCol=ot, all=null), first=2015-04-12, holes=[], latest=2015-04-12) EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=mydb_sales_aggr_fact2, updatePeriod=DAILY, partCol=pt, all=null), first=2015-04-13, holes=[], latest=2015-04-13) EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=local_sales_aggr_fact2, updatePeriod=HOURLY, partCol=dt, all=null), first=2015-04-13-04, holes=[], latest=2015-04-13-05) EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=local_sales_aggr_fact2, updatePeriod=DAILY, partCol=dt, all=null), first=2015-04-11, holes=[], latest=2015-04-12) lens-shell>fact timelines --fact_name sales_aggr_fact2 --storage_name local EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=local_sales_aggr_fact2, updatePeriod=HOURLY, partCol=dt, all=null), first=2015-04-13-04, holes=[], latest=2015-04-13-05) EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=local_sales_aggr_fact2, updatePeriod=DAILY, partCol=dt, all=null), first=2015-04-11, holes=[], latest=2015-04-12) lens-shell>fact timelines --fact_name sales_aggr_fact2 --storage_name local --update_period HOURLY EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=local_sales_aggr_fact2, updatePeriod=HOURLY, partCol=dt, all=null), first=2015-04-13-04, holes=[], latest=2015-04-13-05) lens-shell>fact timelines --fact_name sales_aggr_fact2 --storage_name local --update_period HOURLY --time_dimension delivery_time EndsAndHolesPartitionTimeline(super=PartitionTimeline(storageTableName=local_sales_aggr_fact2, updatePeriod=HOURLY, partCol=dt, all=null), first=2015-04-13-04, holes=[], latest=2015-04-13-05) lens-shell>
Any time you feel that the timeline is out of sync with the actual partitions registered, just set cube.storagetable.partition.timeline.cache.present = false in the storage table's properties and restart lens server. Now this will read all partitions registered for the storage table and re-create the timeline. After creation, it'll update table properties to reflect the correct value.
Metastore API
LENS provides REST api, Java client api and CLI for doing CRUD on metastore.
Query Language
User can query the lens through OLAP Cube QL, which is subset of Hive QL.
Here is the grammar:
CUBE SELECT [DISTINCT] select_expr, select_expr, ...
FROM cube_table_reference
[WHERE [where_condition AND] [TIME_RANGE_IN(colName, from, to)]]
[GROUP BY col_list]
[HAVING having_expr]
[ORDER BY colList]
[LIMIT number]
cube_table_reference:
cube_table_factor
| join_table
join_table:
cube_table_reference JOIN cube_table_factor [join_condition]
| cube_table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN cube_table_reference [join_condition]
cube_table_factor:
cube_name or dimension_name [alias]
| ( cube_table_reference )
join_condition:
ON equality_expression ( AND equality_expression )*
equality_expression:
expression = expression
colOrder: ( ASC | DESC )
colList : colName colOrder? (',' colName colOrder?)*
TIME_RANGE_IN(colName, from, to) : The time range inclusive of ‘from’ and exclusive of ‘to’.
time range clause is applicable only if cube_table_reference has cube_name.
Format of the time range is <yyyy-MM-dd-HH:mm:ss,SSS>
OLAP Cube QL supports all the functions that hive supports as documented in Hive Functions
Query engine provides following features :
- Figure out which dimension tables contain data needed to satisfy the query.
- Figure out the exact fact tables and their partitions based on the time range in the query. While doing this, it will try to minimize computation needed to complete the queries.
- If No Join condition is passed for Joins,join condition will be inferred from the relationship definition.
- Projected fields can be added to group by col list automatically, if not present and if the group by keys specified are not projected, they can be projected
- Automatically add aggregate functions to measures specified as measure's default aggregate.
Various configurations available for running an OLAP query are documented at OLAP query configurations
How to pass timerange in cubeQL
Users have the capability to specify the time range as absolute and relative time in lens cube query. Lens cube query language allows passing timerange at different granularities like secondly, minutely, hourly, daily, weekly, monthly and yearly. Time range is passed in query with the syntax time_range_in(time_dim_name, start_time, end_time). The range is half open. The start time is inclusive and the end time is exclusive.
time_range_in(time_dim_name, start_time, end_time) === start_time <= time_dim_name < end_time
Here is a link to a discussion on time range behaviour
Relative time range
Relative timerange is helpful to the users in scheduling their queries. We'll explain here with example. User can specify the HOURLY granularity with 'now.hour'.
The follwong table tells the available unit granularities and how to specify those granualarities for relative timerange
| UNIT | Specification | Relative time |
|---|---|---|
| Secondly | now.second | now.second+/-30seconds |
| Minutely | now.minute | now.minute+/-30minutes |
| Hourly | now.hour | now.hour+/-3hours |
| Daily | now.day | now.day+/-3days |
| Weekly | now.week | now.week+/-3weeks |
| Monthly | now.month | now.month+/-3months |
| Yearly | now.year | now.year+/-2years |
query execute cube select col1 from cube where TIME_RANGE_IN(col2, "now.hour-4hours", "now.hour") The above queries for the last 4hours data.
Absolute time range
Users can query the data with absolute timerange at different granularities. The following table describes how to specify absoulte timerange at different granularities
| UNIT | Absolute time specification |
|---|---|
| Secondly | yyyy-MM-dd-HH:mm:ss |
| Minutely | yyyy-MM-dd-HH:mm |
| Hourly | yyyy-MM-dd-HH |
| Daily | yyyy-MM-dd |
| Monthly | yyyy-MM |
| Yearly | yyyy |
query execute cube select col1 from cube where TIME_RANGE_IN(it, "2014-12-29-07", "2014-12-29-11") query execute cube select col1 from cube where TIME_RANGE_IN(it, "2014-12-29", "2014-12-30") It queries the data between 29th Dec 2014 and 30th Dec 2014.
Bridge tables
Bridge Table
A bridge table sits between a cube and a dimension or between two dimensions and is used to resolve many-to-many relationships. Refer following for more details :
- Kimball group's definition
- Kimball group's design tip
- Pythian blog
User can specify if any destination link in join-chain maps to many-many relationship during the creation of cube/dimension.
Flattening feature
When we look at the following example :
User :
| ID | Name | Gender |
|---|---|---|
| 1 | A | M |
| 2 | B | M |
| 3 | C | F |
User interests :
| UserID | Sports ID |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 2 | 2 |
| 2 | 3 |
Sports :
| SportsID | Description |
|---|---|
| 1 | Football |
| 2 | Cricket |
| 3 | Basketball |
User Interests is the bridge table which is capturing the many-to-many relationship between Users and Sports. And if we have a fact as follows :
| UserId | Revenue |
|---|---|
| 1 | 100 |
| 2 | 50 |
If analyst is interested in analyzing with respect to user's interested sport, then the report would look the following :
| User's sport | Revenue |
|---|---|
| Football | 150 |
| Cricket | 150 |
| BasketBall | 50 |
Though the individual rows are correct and the overall revenue is actually 150, looking at above report makes people assume that overall revenue is 350. The flattening feature to optionally flatten the selected fields, if fields involved are coming from bridge tables in join path. If flattening is enabled, the report would be the following :
| User Interest | Revenue |
|---|---|
| Football, Cricket | 100 |
| Football, Cricket, BasketBall | 50 |
See configuration params available at OLAP query configurations and look for config related to bridge tables, for turning this on.
Query API
LENS provides REST api, Java client api, JDBC client and CLI for doing submitting queries, checking status and fetching results.