
OLAP Data cube concepts
- OLAP Data cube concepts
- How to pass timerange in cubeQL
- Example queries with relative timerange:
- Example queries with absolute timerange:
Introduction
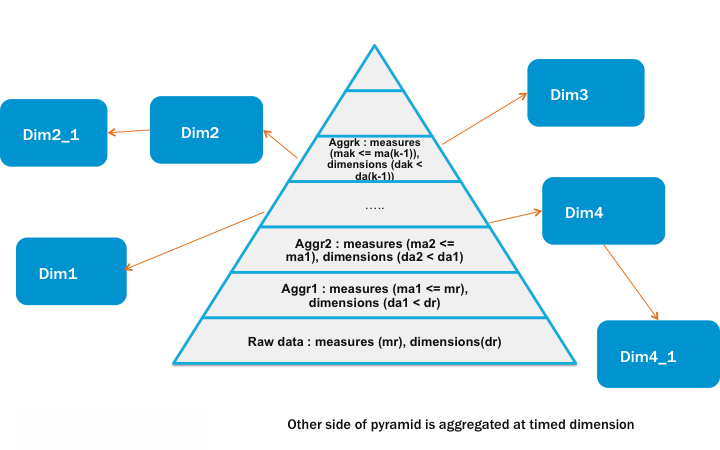
Typical data layout in a data ware house is to have fact data rolled up with time and reduce dimensions at each level. Fact data will have dimension keys sothat it can be joined with actual dimension tables to get more information on dimension attributes.
The typical data layout is depicted in the following diagram.
Lens provides an abstraction to represent above layout, and allows user to define schema of the data at conceptual level and also query the same, without knowing the physical storages and rollups, which is described in below sections.
Metastore model
Metastore model introduces constructs Storage, Cube, Fact table and Dimension table, Partition.
Storage
Storage represents a physical storage. It can be Hadoop File system or a data base. It is defined by name, endpoint and properties associated with.
Cube
A cube is a set of dimensions and measures in a particular subject, which users can query. Cubes also have timed dimensions, which can be used query cube for a time range.
Measure
A measure is a quantity that you are interested in measuring.
Measure will have name, type, default aggregator, a format string, start time and end time. Measure can be simple column measure or an expression measure which is associated with an expression.
Dimension
A dimension is an attribute, or set of attributes, by which you can divide measures into sub-categories.
- A dimension can be as simple as having name and type. // BaseDimension
- A dimension can also refer to a dimension table // ReferencedDimension
- A dimension can be associated with an expression // ExpressionDimension
- A dimension can be a hierarchy of dimensions. // HierachicalDimension
- A dimension can define all the possible values it can take. // InlineDimension
Derived Cube
A derived cube will have subset of measures and dimensions of a base cube. User can query derived cube as well, very similar to cube. For a derived cube, user would specify set of measure names and dimension names only, the definition of measure/dimension will be derived from base cube. All the measures and dimensions of derived cube can always be queried together, whereas all measures and dimensions of parent cube may not be allowed to query together.
Fact Tables
A fact table is table having columns. Columns are subset of measures and dimensions. The fact table is associated with cube, specified by name. Fact can be available in multiple storages. The fact will be used to answer the queries on derived cubes as well.
Dimension tables
A table with list of columns. It can have references to other dimension tables. Theses tables can be joined with cubes while querying. These tables can be available in multiple storages.
Update Period
Fact or dimension tables can be updated at regular intervals. Supports SECONDLY, MINUTELY, HOURLY, DAILY, WEEKLY, MONTHLY, QUARTERLY, YEARLY update periods.
Storage tables
The physical tables, either fact or dimension tables, present on a storage. It will have the same schema as fact/dimension table definition. Each physical table can have its own storage descriptor. These tables can be partitioned by columns. Usually partition columns are dimensions. They can be timed dimensions or other dimensions.
Fact storage table
Fact storage table is the physical fact table for the associated storage, for the specified update period. The storage table can be associated with multiple update periods.
Dimension storage table
Dimension storage table is the physical dimension table for the associated storage. Dimension storage table can have snapshot dumps at specified regular intervals or a table with no dumps, so the storage table can have zero or one update period.
Metastore API
LENS provides REST api, Java client api and CLI for doing CRUD on metastore.
Query Language
User can query the lens through OLAP Cube QL, which is subset of Hive QL.
Here is the grammar:
CUBE SELECT [DISTINCT] select_expr, select_expr, ...
FROM cube_table_reference
[WHERE [where_condition AND] [TIME_RANGE_IN(colName, from, to)]]
[GROUP BY col_list]
[HAVING having_expr]
[ORDER BY colList]
[LIMIT number]
cube_table_reference:
cube_table_factor
| join_table
join_table:
cube_table_reference JOIN cube_table_factor [join_condition]
| cube_table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN cube_table_reference [join_condition]
cube_table_factor:
cube_name or dimension_name [alias]
| ( cube_table_reference )
join_condition:
ON equality_expression ( AND equality_expression )*
equality_expression:
expression = expression
colOrder: ( ASC | DESC )
colList : colName colOrder? (',' colName colOrder?)*
TIME_RANGE_IN(colName, from, to) : The time range inclusive of ‘from’ and exclusive of ‘to’.
time range clause is applicable only if cube_table_reference has cube_name.
Format of the time range is <yyyy-MM-dd-HH:mm:ss,SSS>
OLAP Cube QL supports all the functions that hive supports as documented in Hive Functions
Query engine provides following features :
- Figure out which dimension tables contain data needed to satisfy the query.
- Figure out the exact fact tables and their partitions based on the time range in the query. While doing this, it will try to minimize computation needed to complete the queries.
- If No Join condition is passed for Joins,join condition will be inferred from the relationship definition.
- Projected fields can be added to group by col list automatically, if not present and if the group by keys specified are not projected, they can be projected
- Automatically add aggregate functions to measures specified as measure's default aggregate.
Various configurations available for running an OLAP query are documented at OLAP query configurations
How to pass timerange in cubeQL
Users have the capability to specify the time range as absolute and relative time in lens cube query. Lens cube query language allows passing timerange at different granularities like secondly, minutely, hourly, daily, weekly, monthly and yearly. Relative timerange is helpful to the users in scheduling their queries
User can specify the HOURLY granularity with 'now.hour'.
The follwong table tells the available unit granularities and how to specify those granualarities for relative timerange
| UNIT | Specification | Relative time |
|---|---|---|
| Secondly | now.second | now.second+/-30seconds |
| Minutely | now.minute | now.minute+/-30minutes |
| Hourly | now.hour | now.hour+/-3hours |
| Daily | now.day | now.day+/-3days |
| Weekly | now.week | now.week+/-3weeks |
| Monthly | now.month | now.month+/-3months |
| Yearly | now.year | now.year+/-2years |
Example queries with relative timerange:
query execute cube select col1 from cube where TIME_RANGE_IN(col2, "now.hour-4hours", "now.hour") The above queries for the last 4hours data.
Users can query the data with absolute timerange at different granularities. The following table describes how to specify absoulte timerange at different granularities
| UNIT | Absolute time specification |
|---|---|
| Secondly | yyyy-MM-dd-HH:mm:ss |
| Minutely | yyyy-MM-dd-HH:mm |
| Hourly | yyyy-MM-dd-HH |
| Daily | yyyy-MM-dd |
| Monthly | yyyy-MM |
| Yearly | yyyy |
Example queries with absolute timerange:
query execute cube select col1 from cube where TIME_RANGE_IN(it, "2014-12-29-07", "2014-12-29-11") query execute cube select col1 from cube where TIME_RANGE_IN(it, "2014-12-29", "2014-12-30") It queries the data between 29th Dec 2014 and 30th Dec 2014.
Query API
LENS provides REST api, Java client api, JDBC client and CLI for doing submitting queries, checking status and fetching results.